Estaba equivocado sobre los modelos autoregresivos.
(Este post no está escrito por un LLM)
Todo lo que estamos viviendo en esta semana tiene un punto de inflexión en las industrias creativas. Si bien la generación de imágenes tuvo sus primeros pasos más relevantes en 2015 con DeepDream de Google, donde se generaban imágenes raras como la siguiente:

Fuente: Google DeepDream
En 2021, OpenAI ya nos empieza a deslumbrar con los modelos de difusión para generar imágenes, como es el caso de DALL·E. Esto generó una primera movida grande sobre la generación de imágenes, logrando una calidad sin precedentes para ese entonces, con una capacidad creativa única al combinar distintos estilos y textos, pero con muchas falencias en los detalles. Por ejemplo, las personas con seis dedos.

Fuente: Medium - Why do AI models sometimes produce images with six fingers: https://medium.com/@sanderink.ursina/why-do-ai-models-sometimes-produce-images-with-six-fingers-da4cd53f3313
Un año más tarde, aparece Stability AI con su modelo Stable Diffusion, estableciendo un nuevo estándar en la generación de imágenes hiperrealistas, con alto nivel de detalle y posicionándose como el estado del arte.
Estos modelos funcionan bajo un principio complejo pero relativamente sencillo de entender:
-
Comienzan con ruido (una imagen borrosa, como estática).
-
Van quitando el ruido poco a poco, siguiendo una guía (por ejemplo, un texto).
-
Al final, obtienen una imagen clara que coincide con la guía.
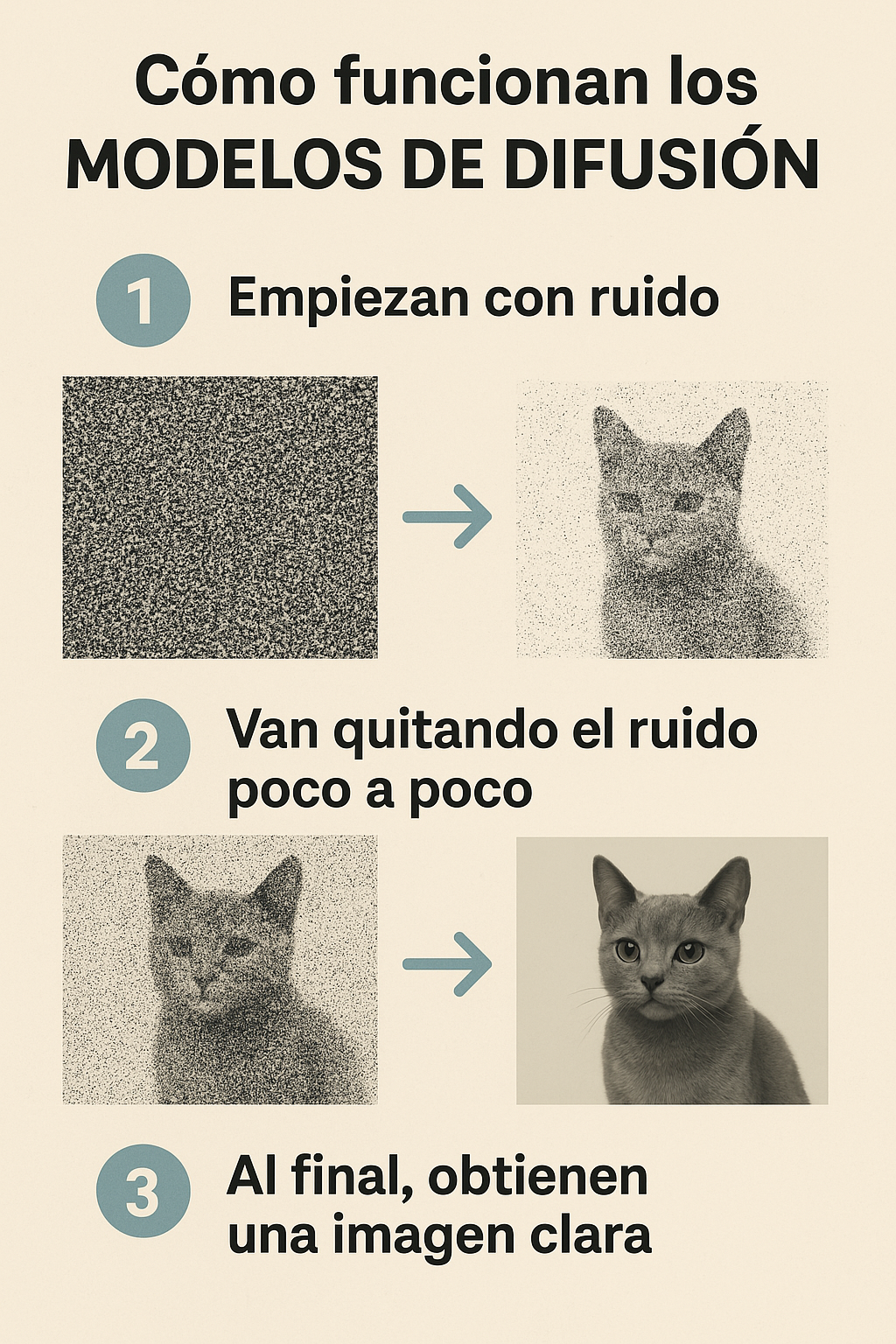
Diffusion Models - Infografía hecha con 4o image gen
Están entrenados con millones de imágenes y sus descripciones para que el modelo aprenda cómo se 'construyen' estas imágenes a partir del ruido. Es como el 'proceso creativo' de estos modelos.
Luego fueron apareciendo otros actores en la industria que vinieron a redefinirla con nuevos modelos que superaban al anterior. Estos son Midjourney, Flux, Adobe Firefly, Leonardo, entre otros.
Pero el problema principal de estos modelos basados en difusión es que, por la naturaleza misma de la arquitectura, es complicado volver a generar la misma imagen agregando otro detalle. Por ejemplo, pedirle que al gato se le agregue un moño. Si bien se ha mejorado muchísimo para poder hacer más estables las salidas de estos modelos, es complicado mantener la consistencia.
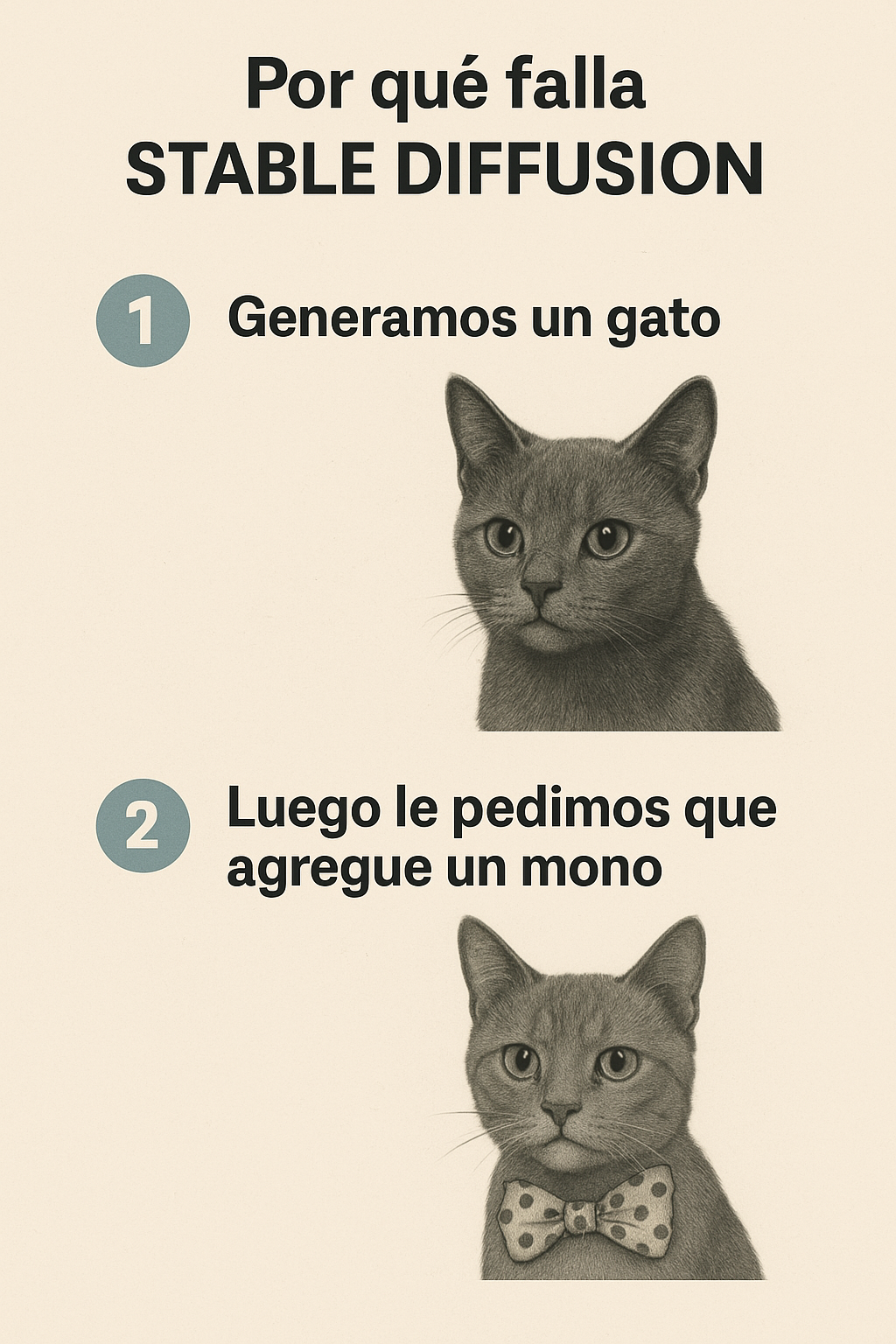
Ejemplo de edición con modelos de difusión
Para atacar este problema, se empezaron a desarrollar muchas técnicas, especialmente las que tienen que ver con transferencias de estilo o, por ejemplo, entrenar con varias imágenes con tu rostro usando ControlNets, LoRAs, IP adapters.
El problema es que esto dejaba afuera a usuarios convencionales no técnicos por la complejidad en poder desarrollar un flujo de trabajo alrededor de estos modelos para que funcionen como queremos.
Para que se hagan una idea, este es un ejemplo de un flujo de trabajo para hacer transferencias de estilos:

Fuente: reddit
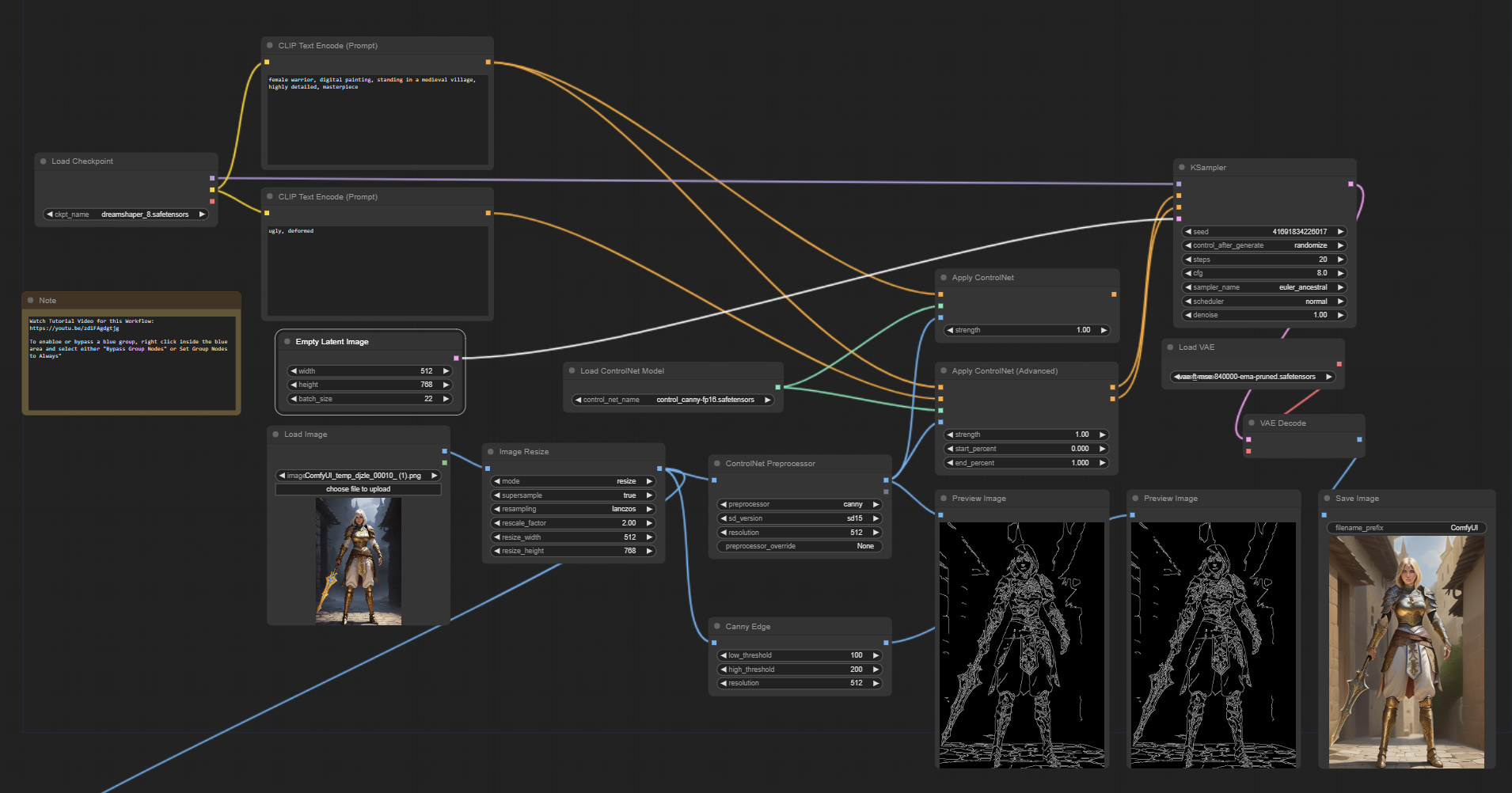
Fuente: OpenART.ai
Se necesitaban otros modelos como estimación de profundidad, detección de bordes u otros algoritmos adicionales de visión por computadora que logren capturar los detalles necesarios para poder mantener consistencia y realizar la difusión solo en las áreas de necesidad. Por ejemplo, si queríamos cambiar la escena, usábamos visión por computadora en el flujo de trabajo para detectar partes claves de la escena y solo pasábamos esa parte por un modelo de difusión para generar, en este caso, la escena y luego terminar de componer la imagen final.
Los modelos de difusión eran muy buenos en los detalles y en crear imágenes hiperrealistas, pero muy malos en poder editar partes específicas y ni hablar si necesitábamos textos en las imágenes.
OpenAI vuelve pero ya no mas con Dall-E
Desde su lanzamiento de los modelos omni (GPT-4o), ya estaban hablando de que estos estaban listos para ser multimodales u omnimodales, es decir, un solo modelo, una sola arquitectura de red neuronal que entiende imágenes, sonidos y textos.
Esto ya nos anticipaba que no solo el entendimiento de imágenes iba a estar bien logrado por este modelo, sino la generación también.
Pero que tiene de diferente este modelo con la de diffusión?
Los modelos 4o tienen una arquitectura basada en transformers y son autoregresivos, es decir, generan sus resultados secuencialmente, token por token o, para ponerlo más fácil, palabra por palabra (así como vemos en los chats con ChatGPT).
Entonces, esta semana, OpenAI lanza 4o Image Generation, su modelo más potente en cuanto a generación de imagen se refiere, dejando totalmente atrás a su antiguo modelo, DALL·E.
Pero la sorpresa que nos llevamos es que este modelo no es uno de difusión, sino que es autoregresivo, es decir, el modelo genera píxeles o grupos de píxeles de forma secuencial para formar la imagen, a diferencia del modelo de difusión que, como recordarán, se forma a partir de un ruido.
Esta forma de generar imagen cambió completamente el juego porque no solo genera imágenes con alto nivel de detalle, sino que tiene un modelo gigante como 4o y su conocimiento para mejorarlo exponencialmente.
Es decir, ahora no necesitamos un flujo de trabajo complejo como el de arriba para editar el detalle de una imagen; simplemente abrimos un chat y comenzamos la edición como verán abajo (o seguro ya vieron por todos lados):
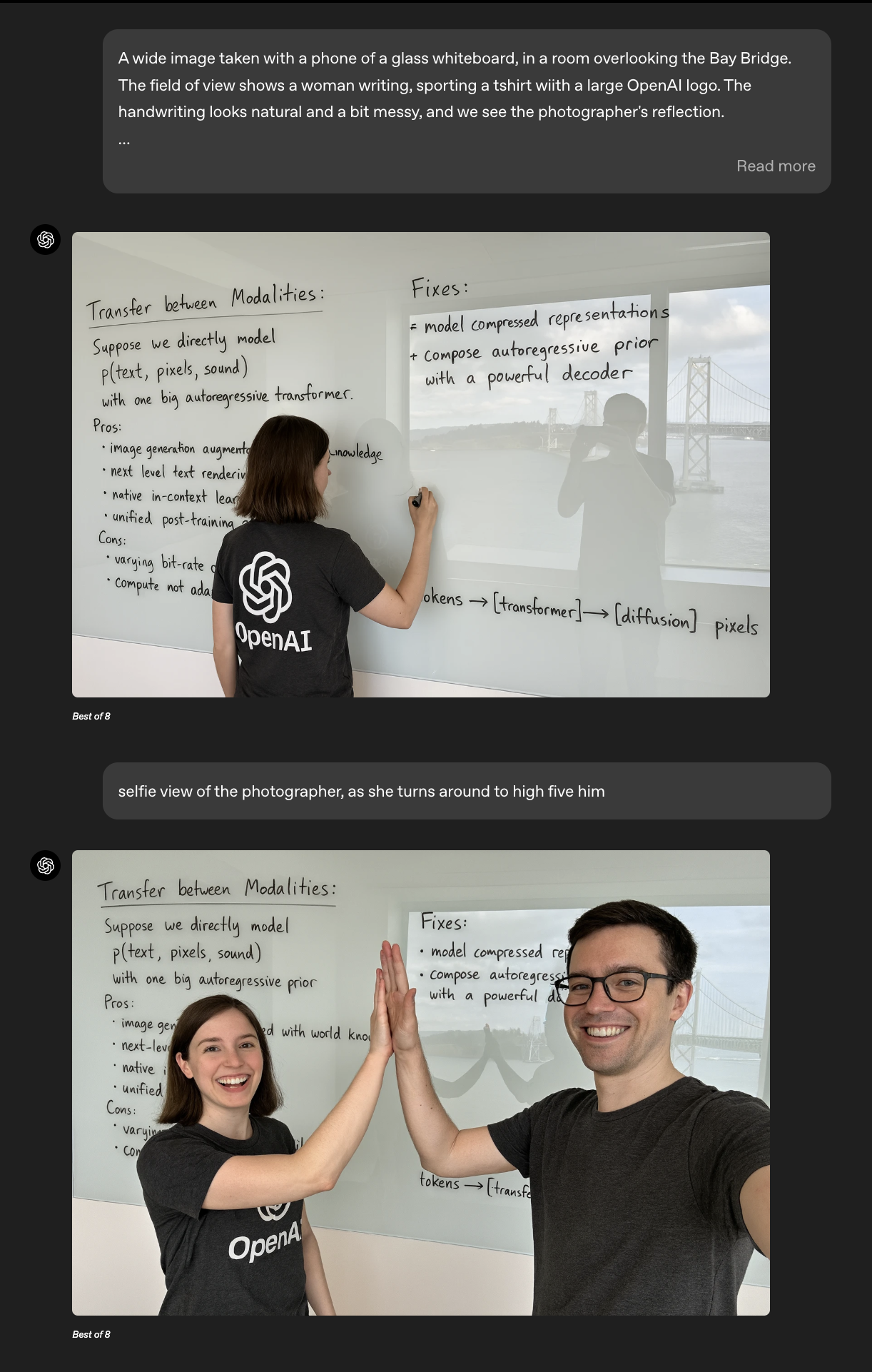
Fuente: OpenAI
La consistencia lograda es impresionante; los textos generados se mantienen casi idénticos, incluso en reflejos, permitiendo que un solo modelo, mediante un simple prompt, realice ediciones complejas que anteriormente requerían un arduo trabajo profesional o flujos de trabajo complicados con modelos de difusión y visión por computadora.
Siento la necesidad de compartir esto porque considero que estamos viviendo el "Claude 3.5" para creativos. Claude 3.5 fue el modelo que revolucionó la industria del software por completo, generando códigos de alta calidad a una velocidad sin precedentes y transformando por completo la forma y rapidez con que desarrollamos productos digitales.
Personalmente, creía que los modelos de difusión representaban el futuro, aunque necesitaban una especie de 'leyes de escalado' para alcanzar consistencia. Sin embargo, ahora veo que tiene completo sentido que los modelos autoregresivos lideren no solo la generación de imágenes, sino también actúen como compañeros de diseño con intuición, toque artístico y sensibilidad, equiparables o incluso superiores a los de un profesional.
Este avance no solo democratiza la creación visual, sino que también abre nuevas posibilidades para artistas y diseñadores, permitiéndoles explorar nuevos horizontes creativos.