Playing with AWS Inferentia Chips
First post attempt
Original blogpost: https://aws.amazon.com/blogs/machine-learning/intuitivo-achieves-higher-throughput-while-saving-on-ai-ml-costs-using-aws-inferentia-and-pytorch/
I'm super excited to share my experience working with the AWS team, especially because I got to contribute to something I really care about - making AI faster and cheaper using their in-house AI chips (AWS Inferentia). Let me tell you about this journey!
The Challenge We Faced
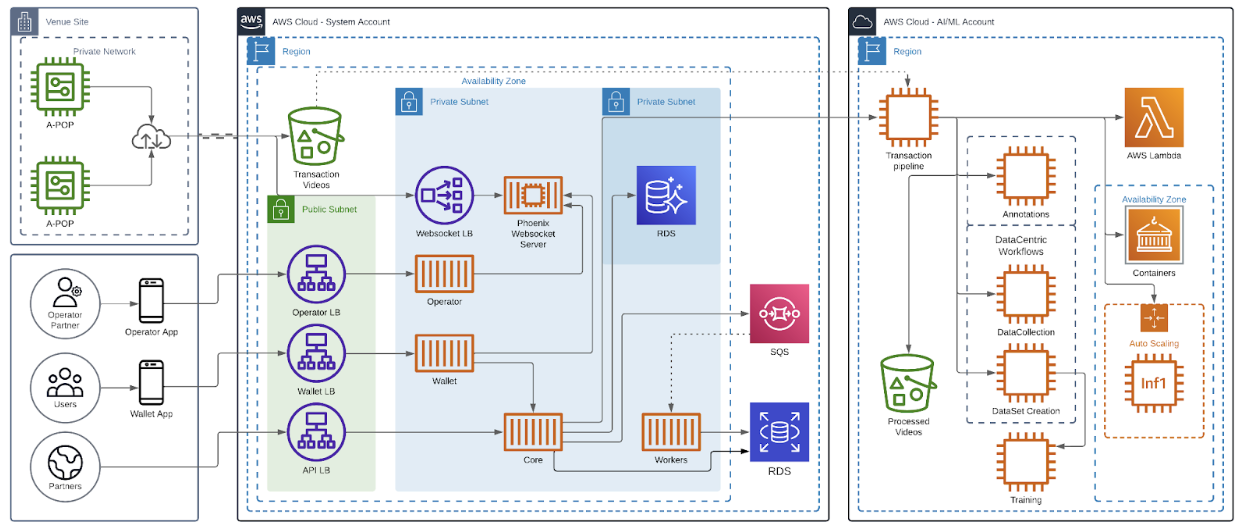
So here's the thing - we needed to make CNN-based architectures fast and cheap in production. Our APOPs (Autonomous Point of Purchase) only use cameras, no other sensors at all. This makes things pretty tricky because we need to understand scenes and actions (kind of like self-driving cars, but for stores!).
Cloud vs Edge: Making the Big Decision
While building our camera-based system for recognizing products and handling payments, we had to make a choice: should we process everything on the edge or in the cloud? After trying different approaches, we went with a cloud-based solution. Here's how it works:
- Customers scan a QR code on the A-POP
- The system unlocks
- They grab what they want and go
- Videos get uploaded to the cloud for processing
- Our AI pipeline handles the rest and charges their account
The Game-Changer: AWS Inferentia
Here's where it gets really interesting! We needed to make our system both fast and cost-effective (because who doesn't want that?). Our AI/ML team was working hard to find the best computer vision models, but we needed a way to run them efficiently.
Enter AWS Inferentia - Amazon's first ML chip designed specifically for deep learning inference. This thing is amazing - it can cut inference costs by up to 70% compared to GPU instances! Here's a bit of code showing how we compile a YOLO model with Neuron:
from ultralytics import YOLO
import torch_neuronx
import torch
batch_size = 1
imgsz = (640, 640)
im = torch.zeros(batch_size, 3, *imgsz).to('cpu') # mock input
# Compiler options
half = True # fp16
fp8 = False
dynamic = False # dynamic batch
f = 'yolov8n.neuronx' # output model name
neuronx_cc_args = ['--auto-cast', 'none']
if half:
neuronx_cc_args = ['--auto-cast', 'all', '--auto-cast-type', 'fp16']
elif fp8:
neuronx_cc_args = ['--auto-cast', 'all', '--auto-cast-type', 'fp8_e4m3']
model = torch.load('yolov8n.pt')['model']
model.eval()
model.float()
model = model.fuse()
neuronx_model = torch_neuronx.trace(
model,
example_inputs=im,
compiler_args=neuronx_cc_args,
)
if dynamic:
neuronx_model = torch_neuronx.dynamic_batch(neuronx_model)
neuronx_model.save(f)
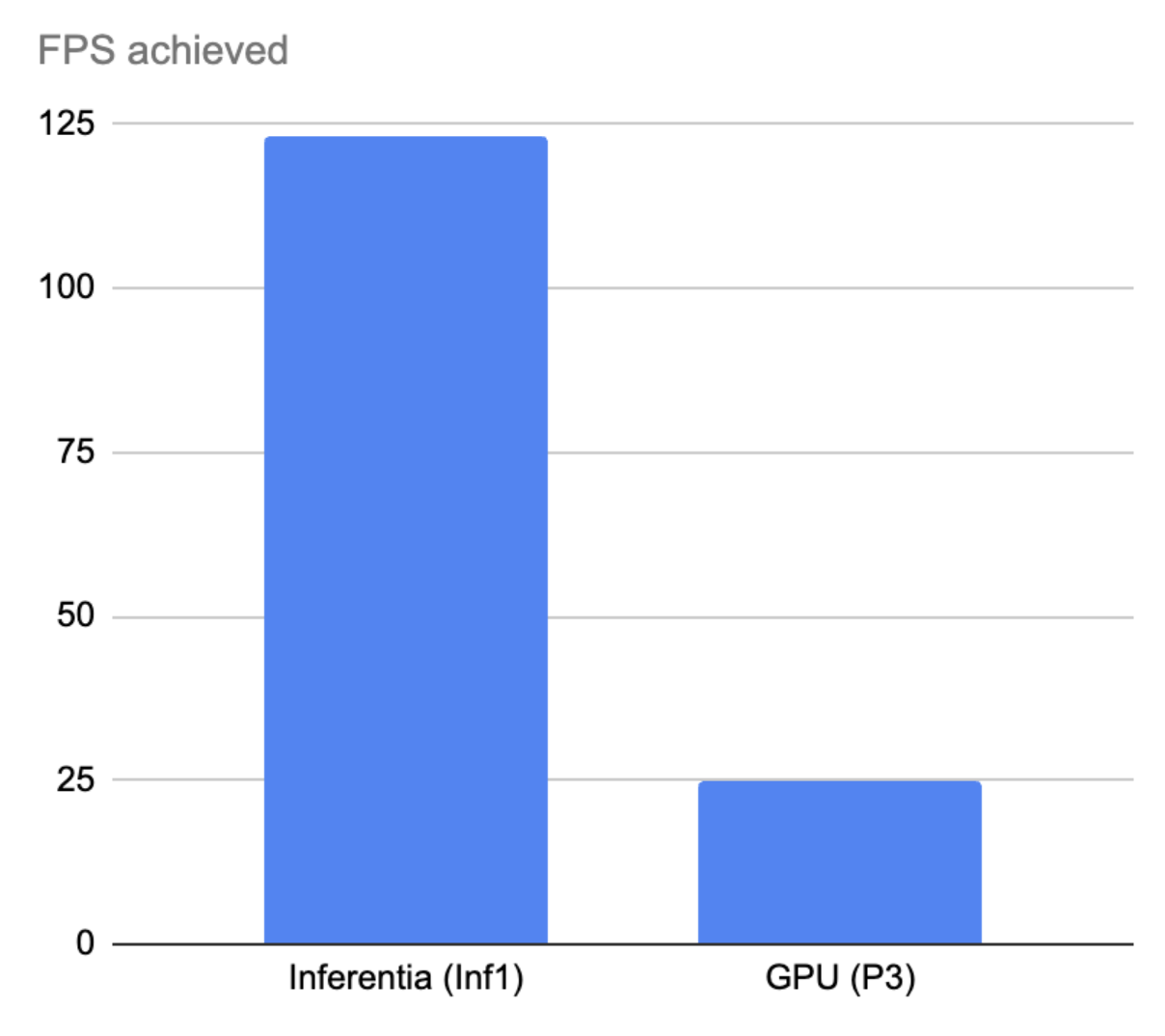
And guess what? The results were mind-blowing:
Our models now run 5x faster (120+ FPS!) We cut costs by 95% (yes, really!) Better accuracy because we can process way more frames
Making Things Even Faster with Data Parallel Inference
To improve performance of our inference workloads and extract maximum performance from AWS Inferentia, we wanted to use all available NeuronCores in the Inferentia accelerator. Achieving this performance was easy to do with the built in tools and apis from the Neuron SDK. We used the torch.neuron.DataParallel(). This Python function implements data parallelism at module level on models created by the PyTorch Neuron API. Data parallelism is a form of parallelization across multiple devices or cores (NeuronCores for Inferentia), referred to as nodes. Each node contains the same model and parameters, but data is distributed across the different nodes. By distributing the data across multiple nodes, data parallelism reduces the total execution time of large batch size inputs compared to sequential execution. Data parallelism works best for models in latency-sensitive applications that have large batch size requirements.
We're already experimenting with AWS Inferentia 2 for even better performance using different transformer-based architectures.